Step 3: Back-End (and AI) Development
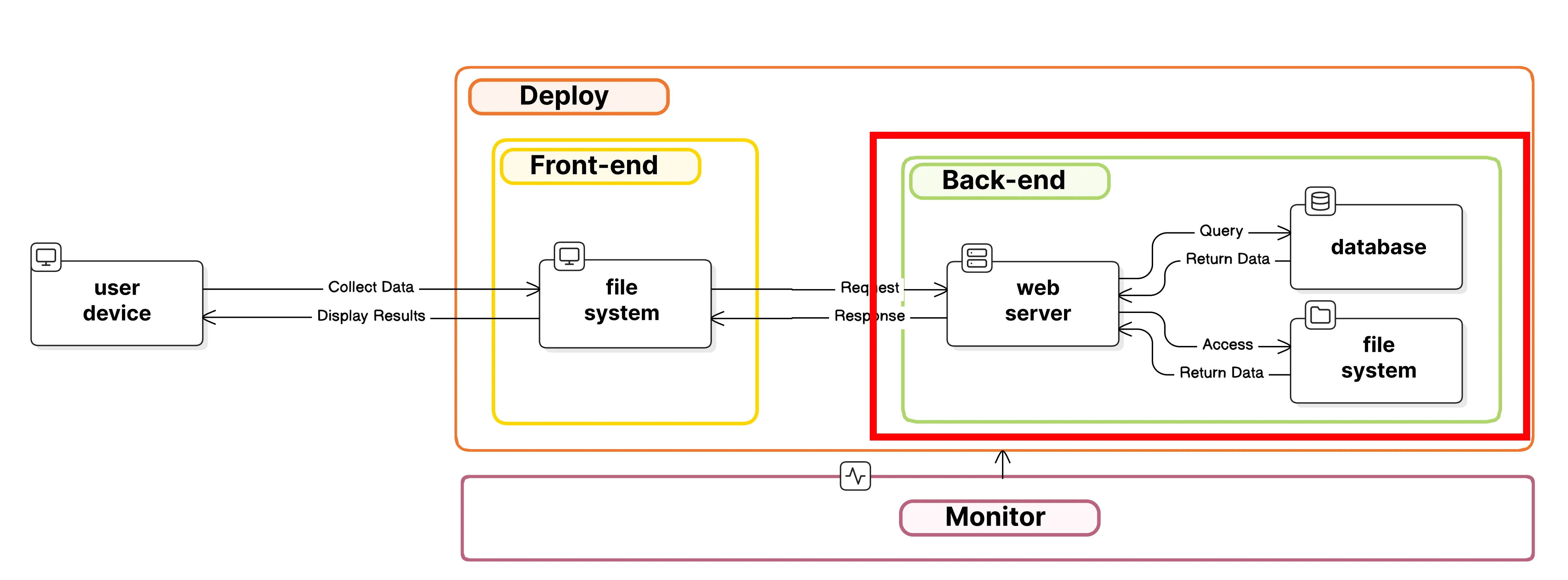
Substeps
- Curating data.
- Database schemas.
- Experimenting with LLMs.
- Test and evaluation of LLM output.
- Caching results (if needed).
- Iteration (if needed).
- Begin preparing all front-end functionality
General Tips
- Version control is your best friend; once you have a version that you’re happy with, use Git to be able to revert back to it!
- Modularize functionality: Keep features and functions loosely coupled to make future changes easier.
- Cache results during development to avoid unnecessary AI API calls.
- It’s super important to understand the functionalities and limitations of the APIs you’re calling (i.e. Reddit scraping). You can use AI to expedite your understanding of what certain libraries and APIs allow you to do (any relevant rate limits, etc.)
- Avoid saving/loading things from temp pickle/json files. Directly use a database since that’s likely what you’ll be using anyways.
- Figure out ground-truth data comparison to validate your AI output is working as expected.
- Test and evaluate the performance as soon as possible, at every step.
- Latency requirements. Think about what can be done offline vs. in real-time. Optimize if needed. Take advantage of asynchronous libraries/tooling.
- Some common things you’ll need to get right with database stuff:
- Dealing with preventing duplication.
- Handling bad inputs
- more?
- Make sure to enable security for database (making sure they’re not writeable by external users).
- Generalization is difficult! You have to keep tweaking AI prompting to make sure inputs and outputs of model are expected across different input types.
App-specific tips
- Use pre-existing libraries for common tasks like scraping or data handling, where possible.
- For emotional sentiment analysis, I had some ideas of which emotions were relevant—leverage AI to enhance your ideas.
Access Denied
You don't have permission to view this content.
Please sign in to access this content.